先上结论:jdk1.8及以前String使用的是char数组,jdk1.9及以后使用的是byte数组。
因为开发人员发现人们使用的字符串值是拉丁字符居多而之前使用的char数组每一个char占用两个字节而拉丁字符只需要一个字节就可以存储,剩下的一个字节就浪费了,造成内存的浪费,gc的更加频繁。因此在jdk9中将String底层的实现改为了byte数组。
在openjdk的开发日志中也是标注了这一改动以及改动的动机。

我们再去jdk中验证一下,先是jdk8

确实底层使用的是char数组。
而到了jdk9时,我们再看
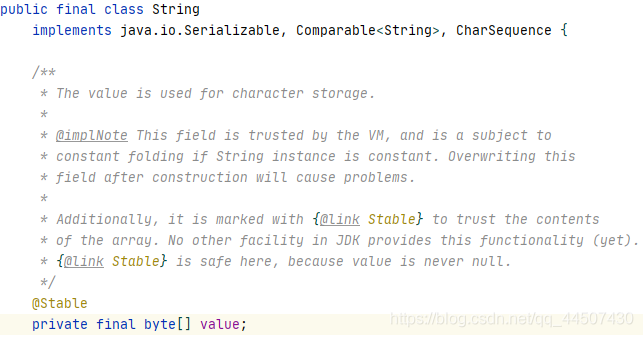
就变成了byte数组。那么问题就来了,String是怎么实现存储汉字的呢?我们将jdk9的源码往下翻看会发现有一个属性
/**
* The identifier of the encoding used to encode the bytes in
* {@code value}. The supported values in this implementation are
*
* LATIN1
* UTF16
*
* @implNote This field is trusted by the VM, and is a subject to
* constant folding if String instance is constant. Overwriting this
* field after construction will cause problems.
*/
private final byte coder;什么?coder?程序员被封装成String的一个属性了?没有买卖就没有伤害,每创建一个String就会有一个程序员失去自由…(手动狗头)
回归正题,在看到上面的注解时,眼前一亮 出现了Latin和UTF16的字眼,我们知道这就是我们要找的那个“她”。注解上说明了该属性共两个实现Latin1和UTF16。
这时候我们就知道要去看构造器了,而我们只需要找到最根源的构造器即可。
看构造器之前我们先看一个属性COMPACT_STRINGS。
翻译过来就是压缩字符串,默认静态代码块赋值true;很明显这个就是决定该String对象是否采用压缩策略的关键属性。
static final boolean COMPACT_STRINGS;
static {
COMPACT_STRINGS = true;
}接下来就是String的构造器
String(char[] value, int off, int len, Void sig) {
//空判断
if (len == 0) {
this.value = "".value;
this.coder = "".coder;
return;
}
//如果开启压缩字符串策略那么就尝试压缩
if (COMPACT_STRINGS) {
byte[] val = StringUTF16.compress(value, off, len);
if (val != null) {
this.value = val;
this.coder = LATIN1;
return;
}
}
//如果没有压缩成功并返回就直接设置为UTF16,我们点进UTF16我们也可以看到下面这两个属性
this.coder = UTF16;
this.value = StringUTF16.toBytes(value, off, len);
}
//点进上面的UTF16找到的两个属性,也就证实了coder属性上面的注解(两个实现)
static final byte LATIN1 = 0;
static final byte UTF16 = 1;最后分享java常见的面试问题,考考大家
String s0="java No.1";
String s1="java ";
String s2="No.1";
String s3="java "+"No.1";
String s4=s1+"No.1";
String s5=s1+s2;
System.out.println(s3==s0);
System.out.println(s4==s0);
System.out.println(s5==s0);
System.out.println(s5==s4);
System.out.println("-----------------------------");
final String s6="I am ";
final String s7="guYue";
String s8="I am guYue";
String s9=s6+s7;
System.out.println(s8==s9);结果如下

大家都答对了吗?
我总结了一下共有以下几种情况:
① “?”+”?”
底层直接优化为“??”
我们使用jclasslib查看以下代码的字节码
String s0="java No.1";
String s1="java ";
String s2="No.1";
String s3="java "+"No.1";
看不懂字节码没有关系,很简单的 比如
1 . ldc就是从常量池中加载字符串到操作数栈中,
2 . astore_1就是将操作数栈中的引用类型变量放到局部变量表中下标为1的位置。
a表示引用变量,store表示存储到局部变量表,_1表示存储在局部变量表哪个位置。
再比如我们现在要将int i=2;放到局部变量表的下标为2的位置,那么字节码指令就是istore_2.
3 . 很明显后面<>包起来的就是具体的字符串。
所以我们现在对应起来看发现s0和s3的加载过程完全相同
②“?”+si ,si+”?” , si+sj
我把这三种归为一类因为都有引用类型加入运算。
这时候底层会new一个StringBuilder再调用append方法,最后调用toString方法完成拼接。这也是为什么禁止在循环中进行+拼接字符串的原因:会new大量的StringBuilder对象,造成效率,资源上的浪费。
我们开如下代码的字节码文件
String s4=s1+"No.1";
invokexxxxxx就是调用方法的意思,其实大家自己猜也能猜出来的。
dup 就是将存在操作数栈上的StringBuilder对象的引用复制一份再压入操作数栈
只要看<>里面的数据再对应源代码就可以知道这一步字节码在干什么了。执行流程与我述说的过程完全一致。
我们最后看一下StringBuilder的toString()方法的源码就知道了,他是new 了一个String并返回所以肯定不是同一个对象。
@Override
public String toString() {
// Create a copy, don't share the array
return new String(value, 0, count);
}③final s1+final s2
这是两个final修饰的String引用的拼接(这个我记忆中好多博客中都没有列举过),我们看如下代码的字节码
final String s6="I am ";
final String s7="guYue";
String s8="I am guYue";
String s9=s6+s7;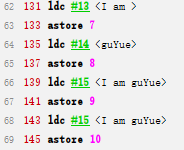
很明显最后两个操作的字节码操作过程都是相同的,即直接从字符串常量池取。所以这里是true。