Part01 正则表达式符号说明
| 符号 | 含义 |
|---|---|
| ^ | 匹配字符串开始位置的字符 |
| $ | 匹配字符串结束位置的字符 |
| . | 匹配任何一个字符 |
| * | 匹配前面的字符出现0~n次 |
| [a,m,u] | 匹配字符a或m或u |
| [a-z] | 匹配所有小写字母 |
| [A-Z] | 匹配所有大写字母 |
| [a-zA-Z] | 匹配所有字母 |
| [0-9] | 匹配所有数字 |
| |特殊符号转义 |
Part02 字符串处理:basename
返回路径字符串中的资源(文件或目录本身)部分
[root@apple w]# basename /aa/bb/cc/dd
dd
如果指定了后缀,basename会帮我们把后缀部分也去掉
[root@apple workspace]# basename /aa/bb/cc/dd.txt .txt
dd
Part03 字符串处理:dirname
返回路径字符串中的目录部分
[root@apple w]# dirname /aa/bb/cc/dd
/aa/bb/cc
Part04 字符串处理:cut
根据指定符号拆分字符串并提取。默认根据 \t 拆分。
- -f 参数:指定要提取的列
- -d 参数:指定拆分依据的字符
准备测试数据:
[root@hadoop101 datas]$ touch cut.txt
[root@hadoop101 datas]$ vim cut.txt
dong shen
guan zhen
wo wo
lai lai
le le
切割提取第一列:
[root@hadoop101 datas]$ cut -d " " -f 1 cut.txt
dong
guan
wo
lai
le
切割提取第二、第三列:
[root@apple w]# cut -d " " -f 2,3 cut.txt
shen
zhen
wo
lai
la
在cut.txt中切出guan
[root@hadoop101 datas]$ cat cut.txt | grep "guan" | cut -d " " -f 1
guan
选取系统 PATH 变量值,第2个 “:” 开始后的所有路径:
命令中的横线表示列数的区间范围。3-表示从第三列开始的所有列;3-5表示第三列到第五列。
[root@hadoop101 datas]$ echo $PATH
/usr/lib64/qt-3.3/bin:/usr/local/bin:/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/sbin:/home/qaqaq/bin
[root@hadoop101 datas]$ echo $PATH | cut -d : -f 3-
/usr/local/bin:/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/sbin:/home/qaqaq/bin
切割ifconfig 后打印的IP地址:
[root@apple w]# ifconfig | grep "netmask" | cut -d "i" -f 2 | cut -d " " -f 2
192.168.41.100
127.0.0.1
192.168.122.1
另一种做法:
[root@apple workspace]# ifconfig | grep netmask | cut -d " " -f 10
192.168.41.100
127.0.0.1
192.168.122.1
Part05 字符串处理:awk
一个强大的文本分析工具,把文件逐行的读入,以空格为默认分隔符将每行切片,切开的部分再进行分析处理。
1、基本用法
awk [选项参数] ‘pattern1{action1} pattern2{action2}…’ filename
pattern:表示AWK在数据中查找的内容,就是匹配模式
action:在找到匹配内容时所执行的一系列命令
使用-F参数指定分隔符。
awk命令的内置变量包括:
| 变量名 | 说明 |
|---|---|
| FILENAME | 文件名 |
| NR | 已读取的记录 |
| NF | 浏览记录的域的个数(切割后,列的个数) |
2、测试
# 准备数据
[root@hadoop101 datas]$ sudo cp /etc/passwd ./
# 搜索passwd文件以root关键字开头的所有行,并输出该行的第7列。
[root@hadoop101 datas]$ awk -F ':' '/root/{print $7}' passwd
/bin/bash
/sbin/nologin
# 搜索passwd文件以root关键字开头的所有行,并输出该行的第1列和第7列,中间以“,”号分割。
[root@hadoop101 datas]$ /bin/bash
/sbin/nologin
root,/bin/bash
# 只显示/etc/passwd的第一列和第七列,以逗号分割,且在第一行显示列名user和shell。在最后一行添加"dahaige,/bin/zuishuai"。
[root@hadoop101 datas]$ awk -F ':' 'BEGIN{print "user\tshell"} /root/{print $1"\t"$7} END{print "pig\t/hello/aaa"}' passwd
user shell
root /bin/bash
operator /sbin/nologin
pig /hello/aaa
# 输出两列数据。第一列:用户id,第二列用户id+1的结果
[root@rich datas]# awk -F ':' '{print $3" "$3+1}' passwd
0 1
1 2
2 3
3 4
4 5
5 6
# 统计 passwd 文件名,每行的行号,每行的列数
[root@rich workspace]# awk -F ':' '/root/{print FILENAME" "$1" "NR" "NF}' passwd
passwd root 1 7
passwd operator 10 7
# 切割IP
[root@apple workspace]# ifconfig | awk -F " " '/netmask/{print $2}'
192.168.41.100
127.0.0.1
192.168.122.1
# 查询sed.txt中空行所在的行号(需要先准备文件,其中包括空行)
[root@hadoop101 datas]$ awk '/^$/{print NR}' sed.txt
5
Part06 字符串处理:sort
sort命令是在Linux里非常有用,它将文件进行排序,并将排序结果标准输出。
| 参数名 | 作用 |
|---|---|
| -n | 依照数值大小排序 |
| -r | 相反顺序排序 |
| -t | 设置排序时使用的分隔字符 |
| -k | 指定需要排序的列 |
# 准备数据
[root@hadoop101 datas]$ touch sort.sh
[root@hadoop101 datas]$ vim sort.sh
bb:40:5.4
bd:20:4.2
xz:50:2.3
cls:10:3.5
ss:30:1.6
# 根据冒号切分,根据第2列排序。列的索引从1开始。
[root@rich workspace]# sort -t ':' -k 2 sort.txt
cls:10:3.5
bd:20:4.2
ss:30:1.6
bb:40:5.4
xz:50:2.3
# 在上例基础上反向排序
[root@rich workspace]# sort -t ':' -rk 2 sort.txt
xz:50:2.3
bb:40:5.4
ss:30:1.6
bd:20:4.2
cls:10:3.5
是否根据数值排序的区别:
# 修改测试数据
bb:40:5.4
uu:2:6.8
bd:20:4.2
xz:50:2.3
cls:10:3.5
ss:30:1.6
# 不使用 -n 参数,根据字符排序
# 只比较第一个字符,1 比 2 小
[root@rich workspace]# sort -t ':' -k 2 sort.txt
cls:10:3.5
bd:20:4.2
uu:2:6.8
ss:30:1.6
bb:40:5.4
xz:50:2.3
# 使用 -n 参数,根据数值排序
# 2 比 10 小
[root@rich workspace]# sort -t ':' -nk 2 sort.txt
uu:2:6.8
cls:10:3.5
bd:20:4.2
ss:30:1.6
bb:40:5.4
xz:50:2.3
Part07 字符串处理:xargs
1、情景举例
①初始状态
某目录下包含下列资源:

②需求
用一条命令删除所有名称中包含“sad”的资源,但是保留sad02
③分步实现
[1]列出全部资源

[2]列出名称中包含“sad”的资源
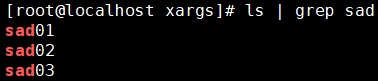
[3]进一步筛选排除sad02

此时最终筛选的结果打印到了标准输出:standard output。通过管道符号可以将标准输出转换为标准输入:standard input。但是删除命令rm不接受标准输入作为参数,只接受命令行参数。什么意思呢?

rm命令前面的管道符号把前面的stdout转换为了stdin再传输给rm命令,这种方式对于有些命令可以,但是有些命令不行。例如:mkdir、ls、rm等命令都是。什么是命令行参数呢?
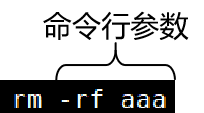
[4]使用xargs命令将stdin转换为命令行参数

2、结论
xargs命令的作用:将管道符号提供的stdin数据转换为后面命令的命令行参数。
3、例子
basename、dirname命令也不接受标准输入,如果我们希望动态处理路径字符串,需要通过xargs进行转换。
# 希望处理的路径字符串由pwd命令动态获取的
[root@rich workspace]# pwd
/root/workspace
# 把pwd命令的结果通过管道直接输入给basename命令,不接受
[root@rich workspace]# pwd | basename
basename: 缺少操作数
Try 'basename --help' for more information.
# 通过xargs命令转换之后,就可以解析了
[root@rich workspace]# pwd | xargs basename
workspace
Part08 企业面试真题
1、京东
①问题1:
使用 Linux 命令查询 file1 中空行所在的行号
[root@hadoop101 datas]$ awk -F ' ' '/^$/{print NR}' sed.txt
5
②问题2:
有文件 chengji.txt 内容如下:
张三 40
李四 50
王五 60
使用Linux命令计算第二列的和并输出
# 执行了计算,但是没打印
[root@rich workspace]# awk -F ' ' '{sum+=$2}' chengji.txt
# 在每一行都做了打印
[root@rich workspace]# awk -F ' ' '{sum+=$2} {print sum}' chengji.txt
40
90
150
# 只在最后一行打印
[root@rich workspace]# awk -F ' ' '{sum+=$2} END{print sum}' chengji.txt
150
提出更高要求:不仅求和,还要打印原始数据内容
[root@rich workspace]# awk -F ' ' '{sum+=$2} BEGIN{print "姓名 分数"} {print $1" "$2} END{print "总分 "sum}' chengji.txt
姓名 分数
张三 40
李四 50
王五 60
总分 150
2、新浪
用shell写一个脚本,对文本中无序的一列数字排序
[root@CentOS6-2 ~]# cat test.txt
9
8
7
6
5
4
3
2
10
1
# 仅排序
[root@rich workspace]# sort -n numbers.txt
1
2
3
4
5
6
7
8
9
10
# 排序后还要计算总和
[root@rich workspace]# sort -n numbers.txt | awk '{sum+=$1} END{print sum}'
55
# 打印原始数据和总和
[root@rich workspace]# sort -n numbers.txt | awk '{sum+=$1} {print "原始数据:"1} END{print "总和:" sum}'
原始数据:1
原始数据:2
原始数据:3
原始数据:4
原始数据:5
原始数据:6
原始数据:7
原始数据:8
原始数据:9
原始数据:10
总和:55
3、金和网络
请用shell脚本写出查找当前文件夹(/home)下所有的文本文件内容中包含有字符”shen”的文件名称
# grep 命令的 -r 参数表示在目录范围内查找
[root@hadoop101 datas]$ grep -r "shen" /home | cut -d ":" -f 1
/home/qaqaq/datas/sed.txt
/home/qaqaq/datas/cut.txt
[root@hadoop101 datas]$ grep -r "shen" /home | cut -d ":" -f 1 | xargs basename
sed.txt
cut.txt
# 使用 grep 命令初步筛选
[root@rich workspace]# grep -r shen ./
./cut.txt:dong shen
# 使用 awk 命令拆分匹配
[root@rich workspace]# grep -r shen ./ | awk -F ':' '{print $1}'
./cut.txt
# 再通过 basename 命令只截取文件名部分
[root@rich workspace]# grep -r shen ./ | awk -F ':' '{print $1}' | xargs basename
cut.txt